最終更新日: 2025.04.01
遅くならないSQLの書き方
目次
SQLが遅くなる要因はいくつもありますが、レコード件数が増えても遅くならないようにインデックスを使うことについて、重点的に説明します。
インデックスとは何か、どのような効果があるのか、インデックスを有効に使うにはどう書けばいいのかなど、DB(データベース)初心者にもわかりやすいように紹介しています。
検索が速いSQLの条件
検索が速いSQLの条件は、主に以下の3つです。
- テーブル内のレコード件数が少ない
- サーバの性能が十分である
- 全検索とならない検索ができている
→インデックスが効いた検索ができている
インデックスについて
インデックスとは
インデックス(素引)とは、データベースの性能を向上させる方法の一つです。
データの格納位を特定し、その位に直接アクセスする事で、検索速度を上げることができます。
インデックスが設定されていない場合の検索では、テーブルの最初から最後まで探すため時間がかかります。
▼10万件のレコードがあるテーブルで、利用日、利用者で検索を行った場合
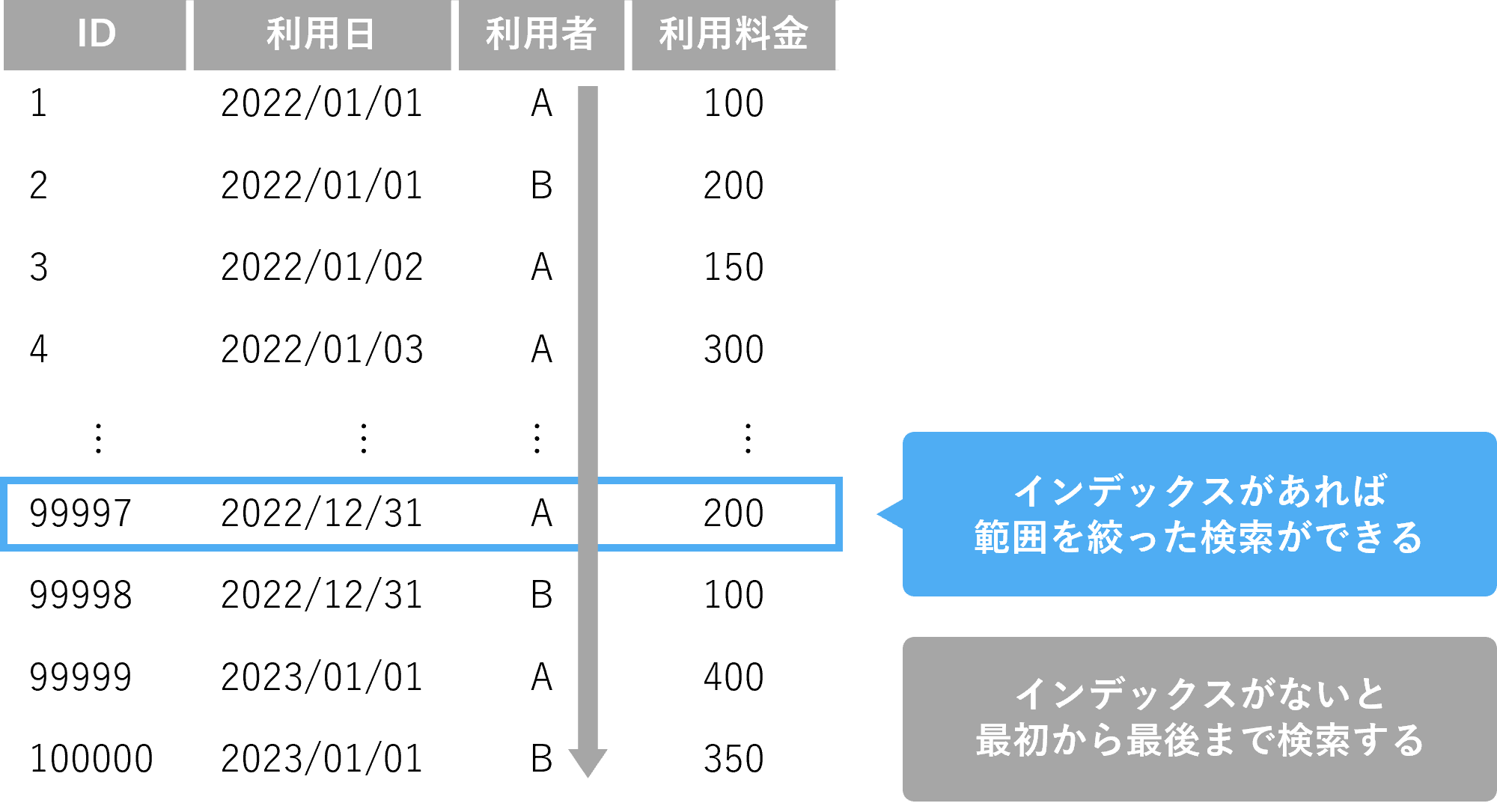
SELECT * FROM table WHERE 利用日 = ‘2022/12/31’ AND 利用者 =‘A’
インデックスがなければ1件目から10万件目までを全検索して該当データを特定して抽出します。
→時間がかかります
利用日と利用者でインデックスが作成されている場合は、該当データに絞った抽出が可能です。
→速いです
インデックスが効いている検索
検索条件に対して有効なインデックスでないと意味がありません。
インデックスに沿った検索条件の場合は威力を発揮しますが、検索条件と無関係、またはインデックスが効かない検索条件の場合は全検索となります。
▼利用日と利用者でインデックスが作成されている場合
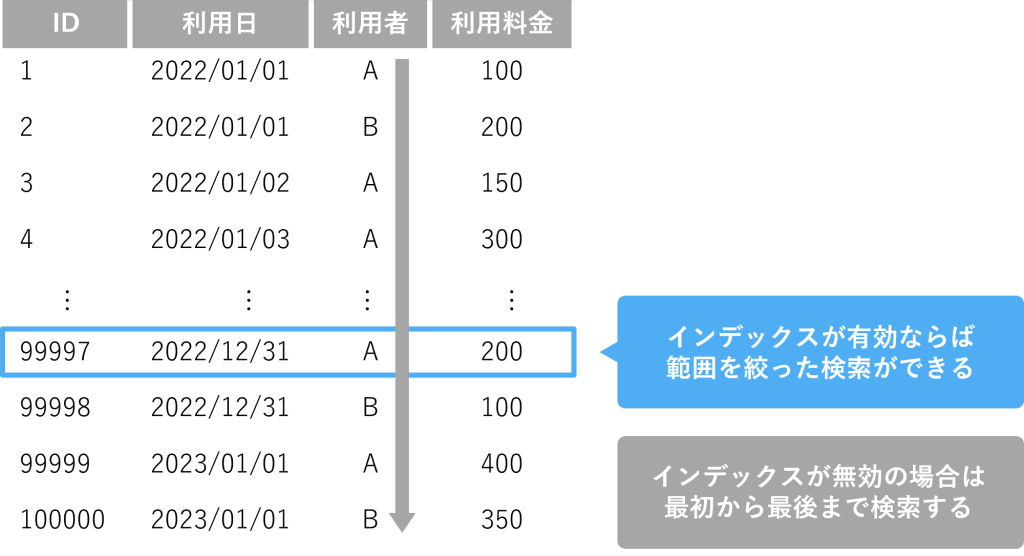
①利用日と利用者で検索
SELECT * FROM table WHERE 利用日 = ‘2022/12/31’ AND 利用者 =‘A’
→インデックスが効く
②利用料金で検索(インデックスに含まれていない)
SELECT * FROM table WHERE 利用料金 = ‘250’
→インデックスが効かない
インデックスは1つの列で作る場合と、複数の列で作る場合があります。複数列でインデックスを作成する場合は、順番の指定が命となります。また、インデックスの順番に沿った検索条件である必要があります。
▼利用日→利用者の順でインデックスが作成されている場合
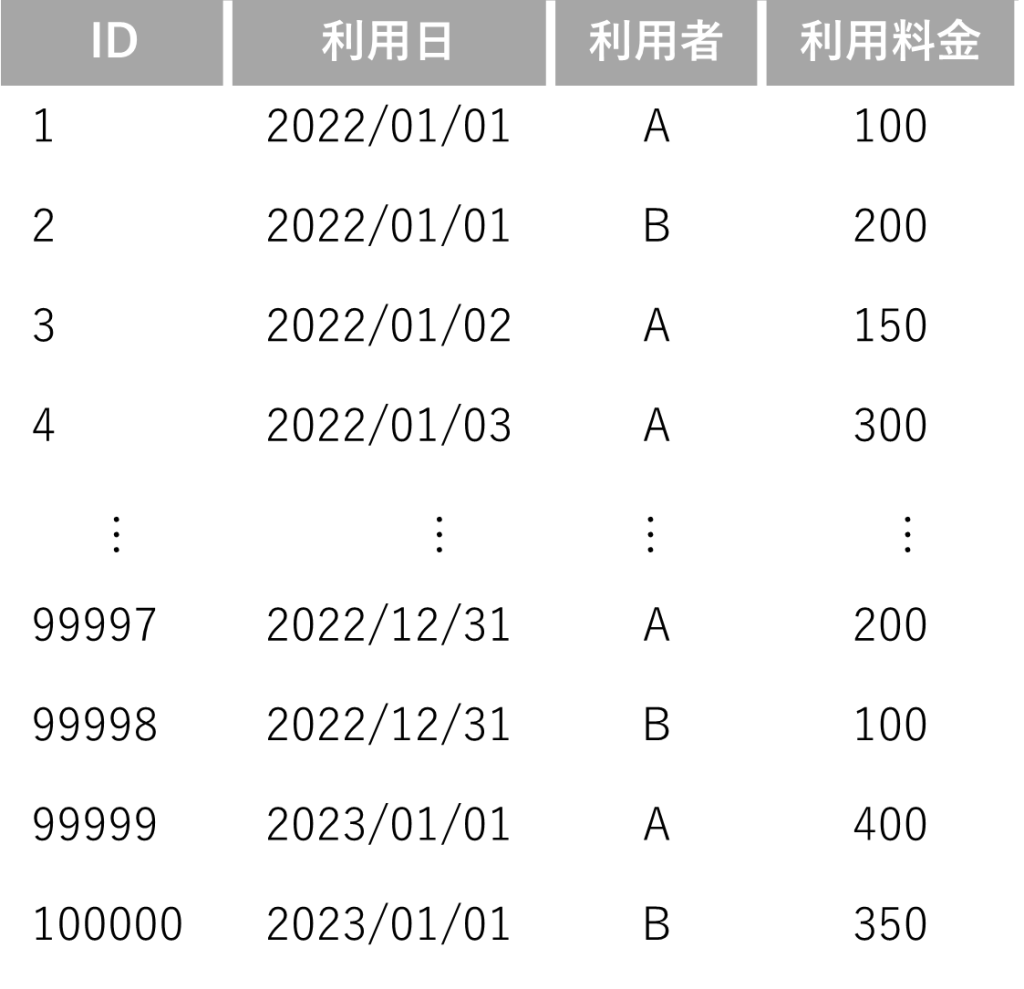
①日付と利用者で検索
SELECT * FROM table WHERE 利用日 = ‘2022/12/31’ AND 利用者 =‘A’
→インデックスが効く
②利用日で検索
SELECT * FROM table WHERE 利用日 = ‘2022/12/31’
→インデックスが効く
③利用者で検索
SELECT * FROM table WHERE 利用者 =‘A’
→インデックスが効かない
複数列でのインデックスの効果範囲
インデックスは最後の1件まで絞れる必要はないと思います。(1件まで絞れるようにインデックスを用意しろと言う人もいます)
システムの検索条件に合わせたインデックスが用意されていれば、ある程度の件数まで絞れるインデックスでも十分な効果はあります。
▼複数列でインデックスを作成し、インデックスの順番が 列A→列B→列Cの場合
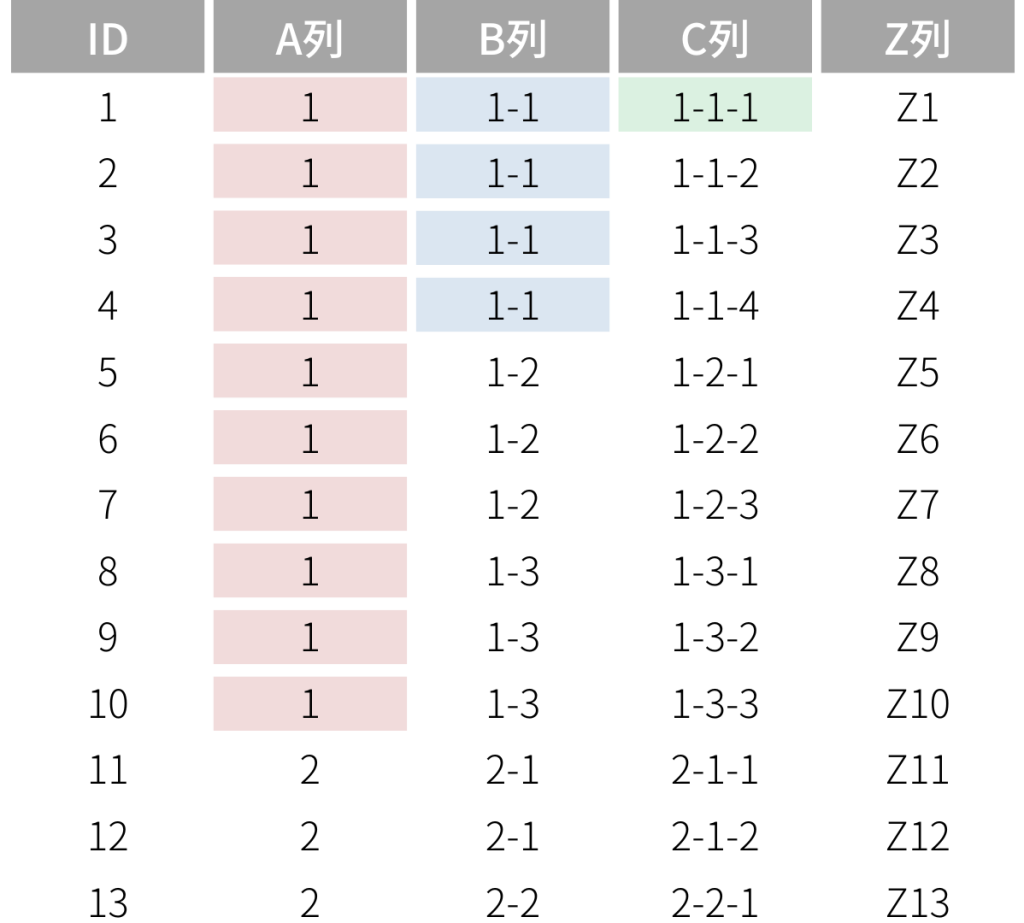
①条件A、B、Cで検索
WHERE A = 1 AND B = 1-1 AND C = 1-1-1
→インデックスが効く ダイレクトに1件まで絞れる
②条件A、Bで検索
WHERE A = 1 AND B = 1-1
→インデックスが効く ダイレクトに4件まで絞れる
③条件A、B、Zで検索
WHERE A = 1 AND B = 1-1 AND Z = Z1
→インデックスが効くが、A→Bまでの範囲で4件までフェッチした結果からZの条件で検索する
④条件A、Cで検索
WHERE A = 1 AND C = 1-1-1
→インデックスが効くが、Aの範囲で10件までフェッチした結果からCを検索する
⑤条件Cで検索
WHERE C = 1-1-1
→インデックスは効かない 全件からCを検索する。この場合は先頭がCの別のインデックスが必要
その他にインデックスが効かないケース
①ORの条件句にインデックス有効外のカラムが指定されている
SELECT * FROM table WHERE 利用日 = ‘2022/12/31’ OR 利用料金 = 250
→利用料金はインデックス化されていない
②LIKE検索(ただし書き方による)
■先頭一致 LIKE ‘ABC%’
→インデックスが効く、ただし文字ABCの該当範囲までをフェッチして、フェッチした中を全検索
■含む LIKE ‘%ABC%’ 、後方一致 LIKE ‘%ABC’
→インデックスが効かない
③カラムで演算、関数を行って検索した場合(ただし右辺での演算はOK)
効かない →SELECT * FROM table WHERE 利用料金 * 1.1 >= 220
効く →SELECT * FROM table WHERE 利用料金 >= 220 / 1.1
効かない →SELECT * FROM table WHERE DATE_FORMAT(利用日, ‘%Y%m’) = ‘202201‘
効く →SELECT * FROM table WHERE 利用日 BETWEEN ‘2022/01/01’ AND ‘2022/01/31’
※TRIMなども注意
④否定形検索 日付 <> ‘2022/12/31’
⑤IS NULL検索、IS NOT NULL検索
DBによってはインデックスが効かない。MySQLは効く。
「EXPLAIN」を使おう
SQLが遅くなってないかを調べる「EXPLAIN」というコマンドがあります。(IPAの読み方では「イクスプレイン」)
SQLの先頭に記述するだけで調査できます。
EXPLAIN SELECT・・・.
◎EXPLAINの詳細
https://free-engineer.life/mysql-explain/
▼インデックスが効いていない

▼インデックスが効いている

豆知識
ORDER BY にもインデックスが有効
ORDER BY を使うと、検索結果を並び替える「Creating sort index」が発生します。
■1000万件から検索して100万件が対象になり、日付順にソートして上位1件だけ持ってくる場合
→抽出した100万件を日付順にソートしてからTOP1件を持ってくる処理が内部(メモリ上)で発生
日付で昇順にする場合、日付にインデックスがあると処理が速くなります。
■ORDER BY 日付, 利用者 とした場合
有効なインデックスは 日付 → 利用者 の順のインデックスのみです。
利用者 →日付 のインデックスはORDER BYには適用されません。
遅いSQL
遅いSQLはインデックスがない、効いていない
環境に問題がないのにSQLが遅いときは、基本的にインデックスが無い・効いていないことがほとんどです。以下のテーブルで説明します。
▼社員テーブル(tbl_staff)
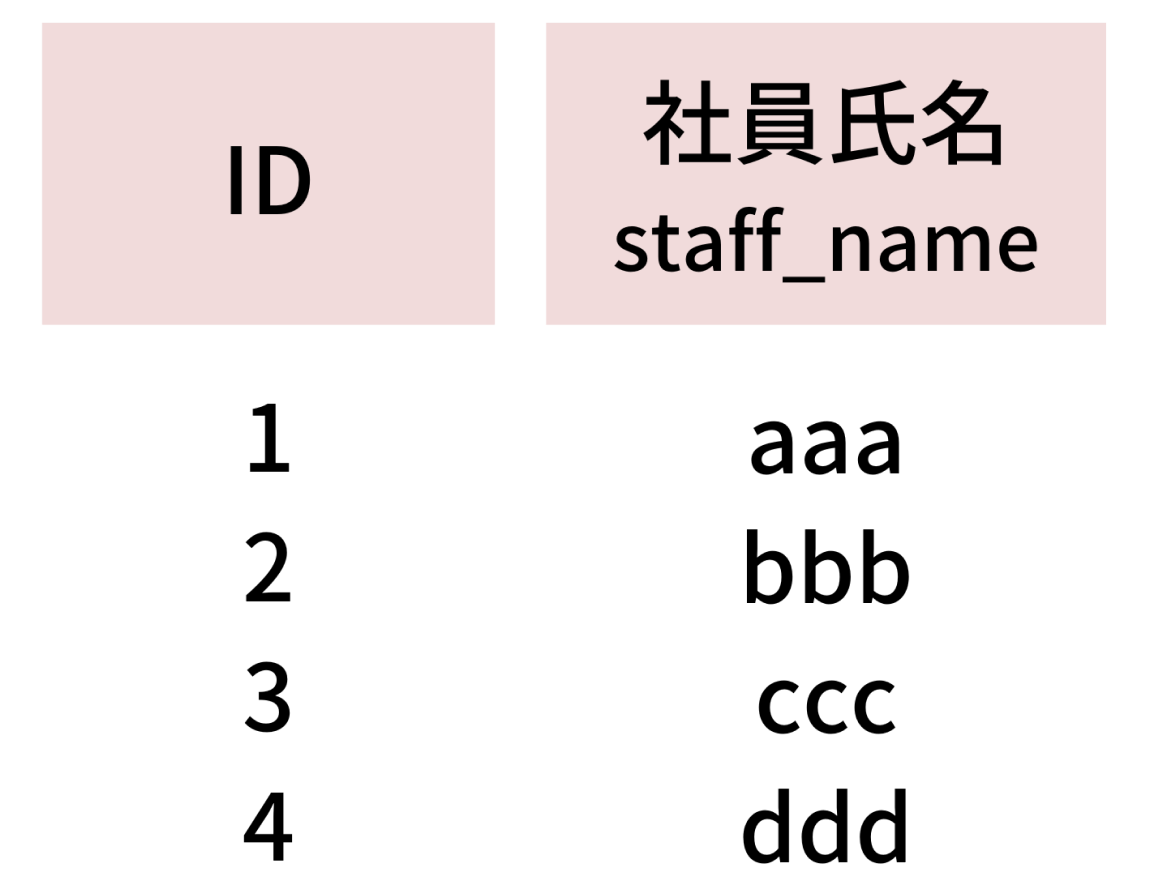
主キー:ID
インデックス なし
レコード4件
▼費用テーブル(tbl_price)
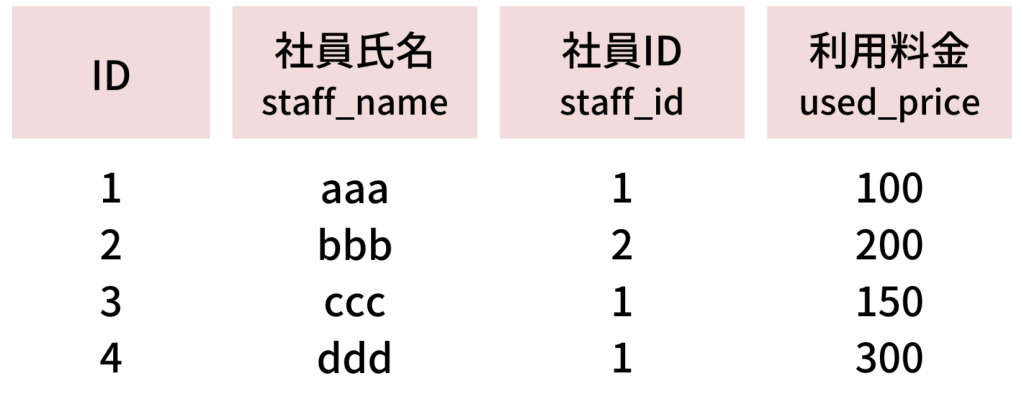
主キー:ID
社員IDで社員テーブルとひも付きます
レコード10万件
JSONを考慮したインデックスが作成されていない
社員テーブルと費用テーブルは社員IDでひも付きます。
結合条件となるカラムには、インデックスを作った方が速くなります。
SELECT * FROM tbl_staff INNER JOIN tbl_price ON tbl_staff.id = tbl_price.staff_id
なお、主キーは自動的にインデックス化されるので、以下の場合は社員テーブルのIDに対するインデックスの指定は不要です。
▼社員テーブル(tbl_staff)主
主キー:ID
インデックス なし
▼費用テーブル(tbl_price)副
主キー:ID
インデックス 社員ID
費用テーブル.社員IDのインデックスの有無で、社員テーブルと費用テーブルをJOINしたSQLを実行して比較します。
ALTER TABLE tbl_price ADD INDEX key_tbl_price_staff(staff_id);
(今回は、インデックスがある「tbl_price_index」とインデックスがない「tbl_price_noindex」のテーブルを用意)
explainコマンドを使ってインデックスの利用状況を確認します。
①インデックスなし(tbl_price_noindex)

②インデックスあり(tbl_price_index)

SELECT
tbl_staff.staff_name , tbl_p.used_date , tbl_p.used_price
FROM
tbl_staff INNER JOIN 費用テーブル tbl_p
ON tbl_staff.id = tbl_p.staff_id
WHERE
tbl_staff.id = 1
①は2行目のtbl_priceのtypeが「ALL」になっていて、全検索になっているのが分かります。
②はインデックスが効いて、フェッチされた行数が全件検索の10万行から4.8万行に減ったのが分かります。JOINするためにtbl_priceを全件見ていたのが、社員IDで絞り込むことが出来ました。
サブクエリの使い方が悪い
インデックスが有効でも、サブクエリを使ってJOINする場合、書き方によっては全検索が走ることがあります。
▼費用テーブルの中を社員ごとに集計し、社員ID「1」の結果だけを表示するSQL
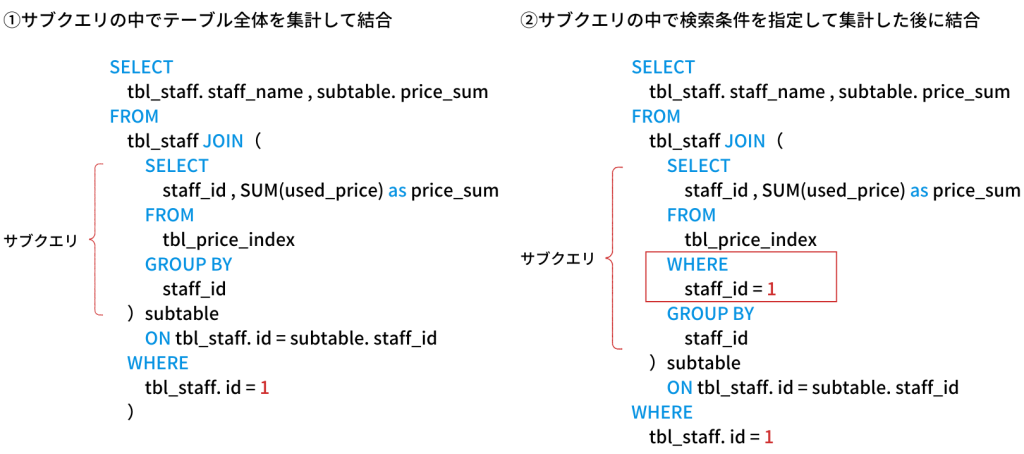
同様に、explainコマンドを使ってインデックスの利用状況を確認します。
費用テーブル.社員IDのインデックスは「有り」の状態です。
①サブクエリの中が全検索になっているパターン
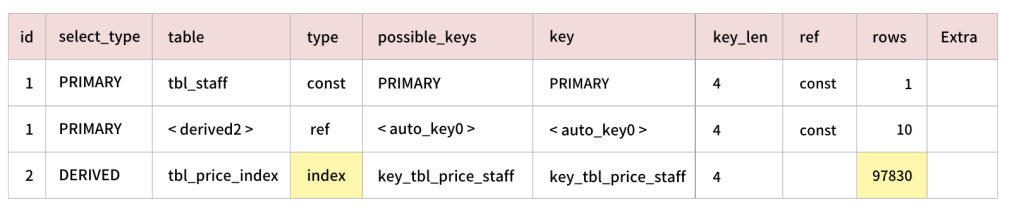
②サブクエリの中でも検索条件を指定したパターン

①サブクエリの中で4人全員の集計を行い、その結果としてJOINして1名に絞る動きになります。
3行目のtypeが「index」になっています。一見良さそうな名前に見えますが、これはフルスキャンが走っています。
②サブクエリの中で社員ID「1」だけを対象として検索、集計を行い、その結果とJOINしました。
インデックスが効いた検索を行ったので、集計対象が9.7万行から4.8万行に減ったのが分かります。
サブクエリの中の結果の件数が多い場合も速度は低下します。
サブクエリの中が10件に絞られ、主のSQLで1件だけを表示する場合 と サブクエリの中が10万件に絞られ、主のSQLで1件だけを表示する場合 とでは、処理の負荷具合が違います。
可能な限り、最終的に抽出される対象と同じ条件でサブクエリ内を絞る方が効率的でしょう。
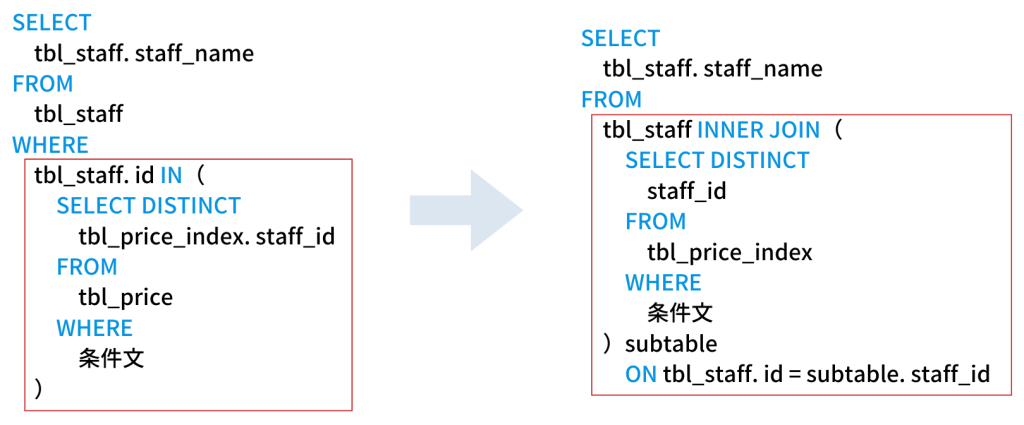
サブクエリの使い方が悪い|IN句
MySQL限定かもしれませんが、IN句とサブクエリを組み合わせるとインデックスが効かない場合があります。下記は実経験からの例文ですが、IN句の中にサブクエリを使っていたSQLをJOIN句での結合に変更したところ、22秒かかっていたSQLが0.2秒に短縮されました。
無駄をへらそう
SELECTの中を必要最低限にして、抽出量を減らしましょう。
カラムが30個あるテーブルで
SELECT * FROM table
としていると、全てのカラムを取り出そうとして負荷がかかります。
使うカラムが数個であれば
SELECT カラム1. カラム2 FROM table
として、無駄な取得を減らしましょう。
件数を確認するためにCOUNT文を使う場合
SELECT COUNT(*) FROM table → SELECT COUNT(1) FROM table
と記述することで、速度が向上します。
